USGS dataretrieval Python Package get_dv() Examples
This notebook provides examples of using the Python dataretrieval package to retrieve daily streamflow data for a United States Geological Survey (USGS) monitoring site. The dataretrieval package provides a collection of functions to get data from the USGS National Water Information System (NWIS) and other online sources of hydrology and water quality data, including the United States Environmental Protection Agency (USEPA).
Install the Package
Use the following code to install the package if it doesn’t exist already within your Jupyter Python environment.
[1]:
!pip install dataretrieval
Requirement already satisfied: dataretrieval in /opt/hostedtoolcache/Python/3.13.13/x64/lib/python3.13/site-packages (0.1.dev1+gf10f08b77)
Requirement already satisfied: requests in /opt/hostedtoolcache/Python/3.13.13/x64/lib/python3.13/site-packages (from dataretrieval) (2.33.1)
Requirement already satisfied: pandas<4.0.0,>=2.0.0 in /opt/hostedtoolcache/Python/3.13.13/x64/lib/python3.13/site-packages (from dataretrieval) (3.0.2)
Requirement already satisfied: numpy>=1.26.0 in /opt/hostedtoolcache/Python/3.13.13/x64/lib/python3.13/site-packages (from pandas<4.0.0,>=2.0.0->dataretrieval) (2.4.4)
Requirement already satisfied: python-dateutil>=2.8.2 in /opt/hostedtoolcache/Python/3.13.13/x64/lib/python3.13/site-packages (from pandas<4.0.0,>=2.0.0->dataretrieval) (2.9.0.post0)
Requirement already satisfied: six>=1.5 in /opt/hostedtoolcache/Python/3.13.13/x64/lib/python3.13/site-packages (from python-dateutil>=2.8.2->pandas<4.0.0,>=2.0.0->dataretrieval) (1.17.0)
Requirement already satisfied: charset_normalizer<4,>=2 in /opt/hostedtoolcache/Python/3.13.13/x64/lib/python3.13/site-packages (from requests->dataretrieval) (3.4.7)
Requirement already satisfied: idna<4,>=2.5 in /opt/hostedtoolcache/Python/3.13.13/x64/lib/python3.13/site-packages (from requests->dataretrieval) (3.13)
Requirement already satisfied: urllib3<3,>=1.26 in /opt/hostedtoolcache/Python/3.13.13/x64/lib/python3.13/site-packages (from requests->dataretrieval) (2.6.3)
Requirement already satisfied: certifi>=2023.5.7 in /opt/hostedtoolcache/Python/3.13.13/x64/lib/python3.13/site-packages (from requests->dataretrieval) (2026.4.22)
Load the package so you can use it along with other packages used in this notebook.
[2]:
from IPython.display import display
from dataretrieval import nwis
import dataretrieval.waterdata as waterdata
Basic Usage
The dataretrieval package has several functions that allow you to retrieve data from different web services. This examples uses the get_dv() function to retrieve daily streamflow data for a USGS monitoring site from NWIS. The following arguments are supported:
Arguments (Additional arguments, if supplied, will be used as query parameters)
sites (string or list of strings): A list of USGS site identifiers for which to retrieve data.
parameterCd (list of strings): A list of USGS parameter codes for which to retrieve data.
statCd (list of strings): A list of USGS statistic codes for which to retrieve data.
start (string): The beginning date for a period for which to retrieve data. If the waterdata parameter startDT is supplied, it will overwrite the start parameter.
end (string): The ending date for a period for which to retrieve data. If the waterdata parameter endDT is supplied, it will overwrite the end parameter.
Example 1: Get daily value data for a specific parameter at a single USGS NWIS monitoring site between a begin and end date.
[3]:
# Set the parameters needed to retrieve data
siteNumber = "10109000" # LOGAN RIVER ABOVE STATE DAM, NEAR LOGAN, UT
parameterCode = "00060" # Discharge
startDate = "2020-10-01"
endDate = "2021-09-30"
# Retrieve the data
dailyStreamflow = waterdata.get_daily(
monitoring_location_id=siteNumber, parameter_code=parameterCode, time=f"{startDate}/{endDate}"
)
print("Retrieved " + str(len(dailyStreamflow[0])) + " data values.")
Retrieved 0 data values.
Interpreting the Result
The result of calling the get_dv() function is an object that contains a Pandas data frame object and an associated metadata object. The Pandas data frame contains the daily values for the observed variable and time period requested. The data frame is indexed by the dates associated with the data values.
Once you’ve got the data frame, there’s several useful things you can do to explore the data.
[4]:
# Display the data frame as a table
display(dailyStreamflow[0])
| geometry | time_series_id | monitoring_location_id | parameter_code | statistic_id | time | value | unit_of_measure | approval_status | qualifier | last_modified | daily_id |
|---|
Show the data types of the columns in the resulting data frame.
[5]:
print(dailyStreamflow[0].dtypes)
geometry object
time_series_id object
monitoring_location_id object
parameter_code object
statistic_id object
time datetime64[s]
value int64
unit_of_measure object
approval_status object
qualifier object
last_modified datetime64[s]
daily_id object
dtype: object
Get summary statistics for the daily streamflow values.
[6]:
dailyStreamflow[0].describe()
[6]:
| time | value | last_modified | |
|---|---|---|---|
| count | 0 | 0.0 | 0 |
| mean | NaT | NaN | NaT |
| min | NaT | NaN | NaT |
| 25% | NaT | NaN | NaT |
| 50% | NaT | NaN | NaT |
| 75% | NaT | NaN | NaT |
| max | NaT | NaN | NaT |
| std | NaN | NaN | NaN |
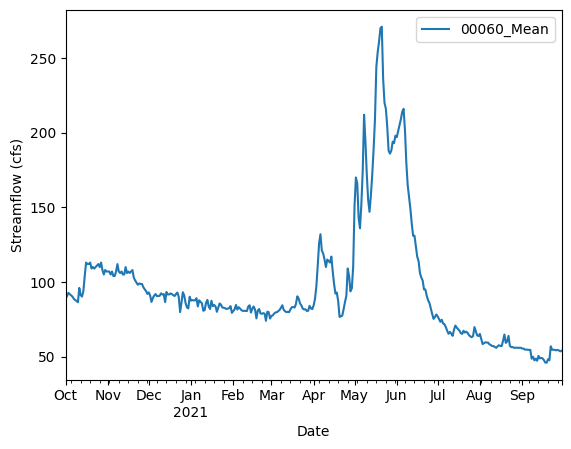
Make a quick time series plot.
[7]:
ax = dailyStreamflow[0].plot(x="time", y="value")
ax.set_xlabel("Date")
ax.set_ylabel("Streamflow (cfs)")
[7]:
Text(0, 0.5, 'Streamflow (cfs)')
The other part of the result returned from the get_dv() function is a metadata object that contains information about the query that was executed to return the data. For example, you can access the URL that was assembled to retrieve the requested data from the USGS web service. The USGS web service responses contain a descriptive header that defines and can be helpful in interpreting the contents of the response.
[8]:
print(
"The query URL used to retrieve the data from NWIS was: " + dailyStreamflow[1].url
)
The query URL used to retrieve the data from NWIS was: https://api.waterdata.usgs.gov/ogcapi/v0/collections/daily/items?monitoring_location_id=10109000¶meter_code=00060&time=2020-10-01%2F2021-09-30&skipGeometry=False&limit=50000
Additional Examples
Example 2: Get daily mean and max discharge and temperature values for a site between a begin and end date.
Parameter Code: 00010 = temperature, 00060 = discharge See https://help.waterdata.usgs.gov/codes-and-parameters/parameters
Statistic Code: 00001 = Maximum, 00003 = Mean See https://help.waterdata.usgs.gov/stat_code
NOTE: There’s not full overlap in the availability of data for temperature and discharge for both statistics at this site. When data for one statistic is not available, a “NaN” value is returned in the data frame.
[9]:
siteID = "04085427"
dailyQAndT = waterdata.get_daily(
monitoring_location_id=siteID,
parameter_code=["00010", "00060"],
time=f"{startDate}/{endDate}",
statistic_id=["00001", "00003"],
)
display(dailyQAndT[0])
| geometry | time_series_id | monitoring_location_id | parameter_code | statistic_id | time | value | unit_of_measure | approval_status | qualifier | last_modified | daily_id |
|---|
Example 3: Get daily mean and max discharge and temperature values for multiple sites between a begin and end date
[10]:
dailyMultiSites = waterdata.get_daily(
monitoring_location_id=["01491000", "01645000"],
parameter_code=["00010", "00060"],
time="2012-01-01/2012-06-30",
statistic_id=["00001", "00003"],
)
display(dailyMultiSites[0])
| geometry | time_series_id | monitoring_location_id | parameter_code | statistic_id | time | value | unit_of_measure | approval_status | qualifier | last_modified | daily_id |
|---|
The following example is the same as the previous example but with multi index turned off (multi_index=False)
[11]:
dailyMultiSites = waterdata.get_daily(
monitoring_location_id=["01491000", "01645000"],
parameter_code=["00010", "00060"],
time="2012-01-01/2012-06-30",
statistic_id=["00001", "00003"],
)
display(dailyMultiSites[0])
| geometry | time_series_id | monitoring_location_id | parameter_code | statistic_id | time | value | unit_of_measure | approval_status | qualifier | last_modified | daily_id |
|---|
Example 4: Test for a site that is not active - returns an empty DataFrame.
[12]:
siteID = "05212700"
notActive = waterdata.get_daily(
monitoring_location_id=siteID, parameter_code="00060", time="2014-01-01/2014-01-07"
)
display(notActive[0])
| geometry | time_series_id | monitoring_location_id | parameter_code | statistic_id | time | value | unit_of_measure | approval_status | qualifier | last_modified | daily_id |
|---|