05: NumPy
This notebook demonstrates how to import and use the Numpy module to work with arrays. The NumPy library includes (among other things) ways of storing and manipulating data that are more efficient than standard Python arrays. Using NumPy with numerical data is much faster than using Python lists or tuples.
Important Note
The data structures and functionality of numpy underly many of the more advanced python tools that we will use including scipy, matplotlib, pandas, geopandas, flopy, and more.
References
Outline
Loading Numpy
Creating a Numpy Array
Array Operations
Accessing Array Elements
Reshaping and Stacking Arrays
Record Arrays
[1]:
import os
from pathlib import Path
import matplotlib.pyplot as plt
#this line sets up the directory paths that we will be using
datapath = Path('data/numpy/')
print('Data will be loaded from the following directory: ', datapath)
Data will be loaded from the following directory: data/numpy
Importing Numpy
The first step is to import the numpy module. It’s not a requirement, but almost a requirement to rename it as np as part of the import statement as follows.
Note that at any time, you can enter the name of an object or method and the “?” to see help. Also remember that shift-tab will bring help.
[2]:
import numpy as np
Many packages, including Numpy, have a __version__ attribute. It is a good idea to be aware of what package version you are using.
[3]:
#To see the version of numpy that was loaded, enter the following command
print('I am running numpy version: ', np.__version__)
I am running numpy version: 2.5.1
Numpy Arrays
Numpy array objects (also called ndarray) are the cental data structure for numpy. Let’s check out how to make arrays:
Convert a list or tuple into an array
Use a numpy function
Read from a file
Creating a Numpy Array from a List
The following is an example of converting a list into a numpy array using the numpy array function.
[4]:
#create a new list
lst = [1, 3, 5, 7]
#convert the list into a new array
a = np.array(lst)
#print some information about the new array
print('The array is: ', a)
print('The type of an array is: ', type(a))
The array is: [1 3 5 7]
The type of an array is: <class 'numpy.ndarray'>
Note that the following does not work. Brackets are required so that the input is a list.
a = np.array(1, 2, 3)
Every array contains additional information that is stored as an attribute as part of the array. These attributes include the dimension (ndim) and the array shape (shape), for example.
[5]:
print('The number of dimensions for a: ', a.ndim)
The number of dimensions for a: 1
[6]:
print('The shape of a: ', a.shape)
The shape of a: (4,)
[7]:
print('The type of a: ', a.dtype)
The type of a: int64
A two-dimensional array can be created by providing two lists within brackets to the numpy array function.
[8]:
#create a new list
lst1 = [1, 3, 5, 7]
lst2 = [9, 12, 14, 32]
#convert the list into a new array
a = np.array([lst1, lst2])
#print some information about the new array
print('The array is: ')
print(a)
print('The type of the array is: ', type(a))
print('The dimension of the array is: ', a.ndim)
print('The shape of the array is: ', a.shape)
The array is:
[[ 1 3 5 7]
[ 9 12 14 32]]
The type of the array is: <class 'numpy.ndarray'>
The dimension of the array is: 2
The shape of the array is: (2, 4)
We could also skip the step of creating two lists and just put them right into the np.array function as follows.
[9]:
np.array([[1, 3, 5, 7],[9, 12, 14, 32]])
[9]:
array([[ 1, 3, 5, 7],
[ 9, 12, 14, 32]])
Array Generating Functions
There are many different functions for creating numpy arrays. They are described here.
Here are a few common array generating functions with links to their descriptions:
empty, zeros, and ones will all create a new array, and they all have the same syntax. The only difference is the value that will be assigned to all of the array elements upon initialization. The syntax for creating an empty array is:
a = np.empty( (shape), dtype )
[10]:
# Create an empty array
print(np.empty((2,2), dtype=int))
[[1 3]
[5 7]]
You are probably asking, what is this junk? When you use np.empty, the only guarantee is that none of the values will be initialized. You’ll get whatever garbage was in that memory address. You will only want to use np.empty if you know that you will be filling the array with meaningful values.
The dtype is the type of array to create. Some common examples are int (INTEGER), float (a floating point, or REAL for you FORTRAN people). Numpy also has some of its own, like np.int32, np.int64, np.float32, np.float64, etc. if you want to specify resolution
Here is an empty float array.
[11]:
a = np.empty((3,3), dtype=float)
print(a)
[[4.68129765e-310 0.00000000e+000 0.00000000e+000]
[0.00000000e+000 0.00000000e+000 0.00000000e+000]
[0.00000000e+000 0.00000000e+000 0.00000000e+000]]
As you might expect, np.zeros and np.ones make arrays with values initialized one zero and one, respectively.
[12]:
print(np.ones((3,3,3), int))
print(np.zeros((2,2,2), float))
[[[1 1 1]
[1 1 1]
[1 1 1]]
[[1 1 1]
[1 1 1]
[1 1 1]]
[[1 1 1]
[1 1 1]
[1 1 1]]]
[[[0. 0.]
[0. 0.]]
[[0. 0.]
[0. 0.]]]
Input and Output
Numpy has a great set of tools for saving arrays to files and reading arrays from files. Details on these tools are here.
The following are the common ones:
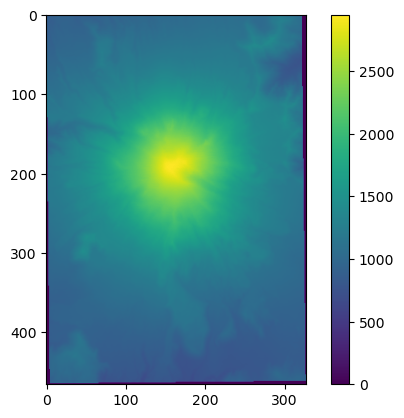
We will now test these functions using data in the data directory. In this folder, there is a file called mt_st_helens_before.dat. This file is a simple text array with a grid of elevations for Mt. St Helens prior to the 1980 eruption. We can read this array using the loadtxt function as follows.
[13]:
before = np.loadtxt(datapath / 'mt_st_helens_before.dat', dtype=np.float32)
print(before.shape, before.dtype)
(466, 327) float32
We can very quickly plot a two-dimensional numpy array using the imshow function from matplotlib. Spoiler alert: we will talk about matplotlib a bunch later.
[14]:
plt.imshow(before)
plt.colorbar()
[14]:
<matplotlib.colorbar.Colorbar at 0x7f0fa20aaa50>
TEST YOUR SKILLS #0
Write the Mt. St. Helens array (before) to a new file called
mynewarray.datin the same folder asmt_st_helens_before.dat. Explore different formats (see the note under documentation for more) and see if you can read it back in again. What are the file size ramifications of format choices?Take a look at
bottom_commented.datin a text editor. What about this file? Can you read this file usingloadtxtwithout having to manually change the file? Hint: look at theloadtxtarguments.
[15]:
#Skill Test 0.0
#use np.savetxt here to write before to mynewarray.dat in the same folder (datapath).
# What other options are there? What are some advantages/disadvantages?
[16]:
#Skill Test 0.1
filename = datapath / 'bottom_commented.dat'
# fill this in
#bot2 =
#print bot2.shape, bot2.dtype
Array Operations
It is very easy to perform arithmetic operations on arrays. So we can easily add and subtract arrays and use them in numpy functions. >pro tip: These operations, generally, are element-wise – so, don’t expect matrix maths to be the result. That comes later…
[17]:
#add
a = np.ones((100, 100))
a = a + 1
print(a)
#powers, division
a = a ** 2.73 / 75
print(a)
[[2. 2. 2. ... 2. 2. 2.]
[2. 2. 2. ... 2. 2. 2.]
[2. 2. 2. ... 2. 2. 2.]
...
[2. 2. 2. ... 2. 2. 2.]
[2. 2. 2. ... 2. 2. 2.]
[2. 2. 2. ... 2. 2. 2.]]
[[0.08846075 0.08846075 0.08846075 ... 0.08846075 0.08846075 0.08846075]
[0.08846075 0.08846075 0.08846075 ... 0.08846075 0.08846075 0.08846075]
[0.08846075 0.08846075 0.08846075 ... 0.08846075 0.08846075 0.08846075]
...
[0.08846075 0.08846075 0.08846075 ... 0.08846075 0.08846075 0.08846075]
[0.08846075 0.08846075 0.08846075 ... 0.08846075 0.08846075 0.08846075]
[0.08846075 0.08846075 0.08846075 ... 0.08846075 0.08846075 0.08846075]]
remember the behavior of lists?
[18]:
a = [1,2,3,4]
a*2
[18]:
[1, 2, 3, 4, 1, 2, 3, 4]
[19]:
a = np.array(a)
a*2
[19]:
array([2, 4, 6, 8])
Lists are general, but numpy is for the maths …
There is so much you can do with numpy arrays and the available functions. For a list of the mathematical functions look here.
[20]:
#or how about a sin function
x = np.linspace(0, 2*np.pi)
y = np.sin(x)
print(x, y)
[0. 0.12822827 0.25645654 0.38468481 0.51291309 0.64114136
0.76936963 0.8975979 1.02582617 1.15405444 1.28228272 1.41051099
1.53873926 1.66696753 1.7951958 1.92342407 2.05165235 2.17988062
2.30810889 2.43633716 2.56456543 2.6927937 2.82102197 2.94925025
3.07747852 3.20570679 3.33393506 3.46216333 3.5903916 3.71861988
3.84684815 3.97507642 4.10330469 4.23153296 4.35976123 4.48798951
4.61621778 4.74444605 4.87267432 5.00090259 5.12913086 5.25735913
5.38558741 5.51381568 5.64204395 5.77027222 5.89850049 6.02672876
6.15495704 6.28318531] [ 0.00000000e+00 1.27877162e-01 2.53654584e-01 3.75267005e-01
4.90717552e-01 5.98110530e-01 6.95682551e-01 7.81831482e-01
8.55142763e-01 9.14412623e-01 9.58667853e-01 9.87181783e-01
9.99486216e-01 9.95379113e-01 9.74927912e-01 9.38468422e-01
8.86599306e-01 8.20172255e-01 7.40277997e-01 6.48228395e-01
5.45534901e-01 4.33883739e-01 3.15108218e-01 1.91158629e-01
6.40702200e-02 -6.40702200e-02 -1.91158629e-01 -3.15108218e-01
-4.33883739e-01 -5.45534901e-01 -6.48228395e-01 -7.40277997e-01
-8.20172255e-01 -8.86599306e-01 -9.38468422e-01 -9.74927912e-01
-9.95379113e-01 -9.99486216e-01 -9.87181783e-01 -9.58667853e-01
-9.14412623e-01 -8.55142763e-01 -7.81831482e-01 -6.95682551e-01
-5.98110530e-01 -4.90717552e-01 -3.75267005e-01 -2.53654584e-01
-1.27877162e-01 -2.44929360e-16]
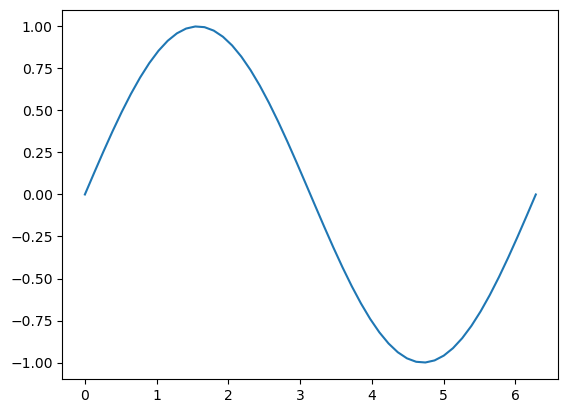
[21]:
# An x, y plot can be quickly generated using plt.plot()
plt.plot(x, y)
[21]:
[<matplotlib.lines.Line2D at 0x7f0fa1fc1550>]
Accessing Array Elements
Okay, now for the good stuff…
Numpy arrays are zero based, which means the first position is referenced as 0. If you are a FORTRAN person or a MATLAB person, THIS WILL CAUSE YOU GREAT GRIEF! You will be burned by the fact that the first element in an array is not a[1]. It is a[0]. You will accept it, eventually, and then you will find zero-based arrays to be more intuitive, maybe.
Let’s do some array slicing to see how all of this works.
[22]:
#create an array with 10 equally spaced values
a = np.linspace(50, 60, 10)
print(a)
[50. 51.11111111 52.22222222 53.33333333 54.44444444 55.55555556
56.66666667 57.77777778 58.88888889 60. ]
[23]:
#we can access the first value as
print('The first value is: ', a[0])
#the last value is
print('The last value is: ', a[9])
The first value is: 50.0
The last value is: 60.0
Okay, this is all good. Now there is another cool part of numpy arrays, and that is that we can use negative index numbers. So instead of a[9], we could also say a[-1].
[24]:
print('The last value is: ', a[-1])
#hmm. Does that mean? yup.
print('The second to last value is: ', a[-2])
The last value is: 60.0
The second to last value is: 58.888888888888886
Accessing Parts of an Array
So how do we access parts of an array? The formal syntax for a one dimensional array is:
array[idxstart : idxstop : idxstride]
where idxstart is the zero-based array position to start; idxstop is the zero-based index to go up to, BUT NOT INCLUDE, and idxstride is the number of values to skip. The following are valid array slides:
a[:] #all elements
a[0:-1] #all elements
a[2:10] #elements in the third position up to elements in the 10th position
a[::2] #start in position 0 and include every other element
a[::-1] #start at the end and reverse the order
The following are some examples.
[25]:
#make a fresh array with 30 values
a = np.arange(30)
print('a=', a)
#print values from the beginning up to but not including the 10th value
print('a[:10]: ', a[:10])
#or print the values from position 20 to the end
print('a[20:]', a[20:])
a= [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
24 25 26 27 28 29]
a[:10]: [0 1 2 3 4 5 6 7 8 9]
a[20:] [20 21 22 23 24 25 26 27 28 29]
This is all good, but what if want to skip over values. Then we can also enter a stride.
[26]:
# Print every second value
print(a[::2])
[ 0 2 4 6 8 10 12 14 16 18 20 22 24 26 28]
[27]:
# Print every 5th value from 5 to 25
print(a[5::5])
[ 5 10 15 20 25]
Note the slice notation 5::5 above is actually shorthand for the built-in slice object
[28]:
a[slice(10, None, 5)]
[28]:
array([10, 15, 20, 25])
And this all works for multi-dimensional arrays as well. So we can access parts of a multi-dimensional array, just separate the slice commands with a ','
[29]:
a = np.ones((10, 10), dtype=int)
print(a)
[[1 1 1 1 1 1 1 1 1 1]
[1 1 1 1 1 1 1 1 1 1]
[1 1 1 1 1 1 1 1 1 1]
[1 1 1 1 1 1 1 1 1 1]
[1 1 1 1 1 1 1 1 1 1]
[1 1 1 1 1 1 1 1 1 1]
[1 1 1 1 1 1 1 1 1 1]
[1 1 1 1 1 1 1 1 1 1]
[1 1 1 1 1 1 1 1 1 1]
[1 1 1 1 1 1 1 1 1 1]]
[30]:
#now lets set the upper left quadrant of a to 2
a[:5, :5] = 2
print(a)
[[2 2 2 2 2 1 1 1 1 1]
[2 2 2 2 2 1 1 1 1 1]
[2 2 2 2 2 1 1 1 1 1]
[2 2 2 2 2 1 1 1 1 1]
[2 2 2 2 2 1 1 1 1 1]
[1 1 1 1 1 1 1 1 1 1]
[1 1 1 1 1 1 1 1 1 1]
[1 1 1 1 1 1 1 1 1 1]
[1 1 1 1 1 1 1 1 1 1]
[1 1 1 1 1 1 1 1 1 1]]
Accessing Array Elements Using an Index List or Array
If we know the array indices that we want to access, we can specify them in a list and pass that list to the array through the brackets.
[31]:
a = np.random.random(10)
print(a)
print('values in 2, 3, and 7 positions', a[[2, 3, 7]])
[0.92862654 0.22618864 0.47568956 0.18177294 0.61991257 0.69665525
0.12853466 0.29093516 0.55655425 0.09486502]
values in 2, 3, and 7 positions [0.47568956 0.18177294 0.29093516]
[32]:
#this also works for multi dimensions
icoord = np.arange(10)
jcoord = icoord
a = np.zeros((10, 10), dtype='int')
a[icoord, jcoord] = 1
print(a) #hey, its the identity matrix!
#what do you think? Do you think numpy has an identity function?
[[1 0 0 0 0 0 0 0 0 0]
[0 1 0 0 0 0 0 0 0 0]
[0 0 1 0 0 0 0 0 0 0]
[0 0 0 1 0 0 0 0 0 0]
[0 0 0 0 1 0 0 0 0 0]
[0 0 0 0 0 1 0 0 0 0]
[0 0 0 0 0 0 1 0 0 0]
[0 0 0 0 0 0 0 1 0 0]
[0 0 0 0 0 0 0 0 1 0]
[0 0 0 0 0 0 0 0 0 1]]
[33]:
np.eye(10)
[33]:
array([[1., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 1., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 1., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 1., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 1., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 1., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 1., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 1., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 1., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 1.]])
Boolean indexing
conditional statements can also be used to slice arrays what if we want to identify nodata in the Mt. St. Helens array, which have a value of 0, and convert them to nodata?
[34]:
before
[34]:
array([[ 0., 0., 0., ..., 0., 0., 0.],
[ 0., 0., 0., ..., 0., 0., 0.],
[867., 872., 881., ..., 0., 0., 0.],
...,
[ 0., 0., 0., ..., 0., 0., 0.],
[ 0., 0., 0., ..., 0., 0., 0.],
[ 0., 0., 0., ..., 0., 0., 0.]],
shape=(466, 327), dtype=float32)
comparing arrays
Value Comparisons yield Boolean True/False results and include ==,<,<=,>=,!= (the last being “not equal”)
[35]:
before==0
[35]:
array([[ True, True, True, ..., True, True, True],
[ True, True, True, ..., True, True, True],
[False, False, False, ..., True, True, True],
...,
[ True, True, True, ..., True, True, True],
[ True, True, True, ..., True, True, True],
[ True, True, True, ..., True, True, True]], shape=(466, 327))
[36]:
before != 0
[36]:
array([[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[ True, True, True, ..., False, False, False],
...,
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False],
[False, False, False, ..., False, False, False]], shape=(466, 327))
[37]:
# use a Boolean result to operate on an array
before[before == 0] = np.nan
[38]:
before
[38]:
array([[ nan, nan, nan, ..., nan, nan, nan],
[ nan, nan, nan, ..., nan, nan, nan],
[867., 872., 881., ..., nan, nan, nan],
...,
[ nan, nan, nan, ..., nan, nan, nan],
[ nan, nan, nan, ..., nan, nan, nan],
[ nan, nan, nan, ..., nan, nan, nan]],
shape=(466, 327), dtype=float32)
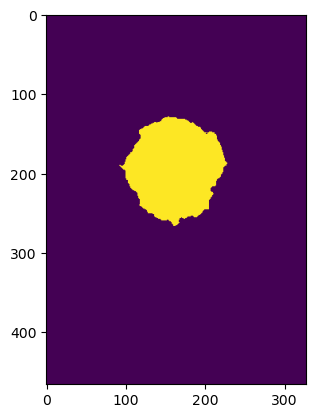
or, what if we want to identify cells with elevations above 2000 meters? before > 2000 returns True for each position in the array that meets this condition (yellow in plot below), False everywhere else (purple)
[39]:
plt.imshow(before > 2000)
[39]:
<matplotlib.image.AxesImage at 0x7f0fa1ea5450>
this can be applied, element-by-element to entire arrays
[40]:
a = np.random.random((5,5))
b = a.copy()
c = b.copy()
c[0,0] = 99 # tweak a single entry in c
[41]:
a==b
[41]:
array([[ True, True, True, True, True],
[ True, True, True, True, True],
[ True, True, True, True, True],
[ True, True, True, True, True],
[ True, True, True, True, True]])
[42]:
b==c
[42]:
array([[False, True, True, True, True],
[ True, True, True, True, True],
[ True, True, True, True, True],
[ True, True, True, True, True],
[ True, True, True, True, True]])
[43]:
# are they the same shape and have all the same values
np.array_equal(a, b), np.array_equal(b,c)
[43]:
(True, False)
Logical operations: any and all
[44]:
np.any(a==c), np.all(a==c)
[44]:
(np.True_, np.False_)
Bitwise operations are required to compare Boolean (and other binary) arrays and include “and” & and “or” |.
[45]:
# compare two binary arrays
a=np.random.random((5,5))
little = a<.2
big = a>.6
[46]:
little
[46]:
array([[ True, False, False, False, False],
[False, False, False, False, False],
[False, False, False, False, False],
[False, True, False, False, False],
[ True, False, False, False, False]])
[47]:
big
[47]:
array([[False, False, True, False, True],
[False, True, True, True, True],
[ True, False, True, True, False],
[False, False, False, True, False],
[False, True, True, False, True]])
[48]:
little & big # can't be both, right?
[48]:
array([[False, False, False, False, False],
[False, False, False, False, False],
[False, False, False, False, False],
[False, False, False, False, False],
[False, False, False, False, False]])
[49]:
little | big
[49]:
array([[ True, False, True, False, True],
[False, True, True, True, True],
[ True, False, True, True, False],
[False, True, False, True, False],
[ True, True, True, False, True]])
[50]:
a[little | big] = 0
a
[50]:
array([[0. , 0.4062624 , 0. , 0.51396335, 0. ],
[0.4718058 , 0. , 0. , 0. , 0. ],
[0. , 0.35918105, 0. , 0. , 0.2838194 ],
[0.33237827, 0. , 0.48912335, 0. , 0.3216974 ],
[0. , 0. , 0. , 0.40970948, 0. ]])
pro tip: If you stack the comparison together with bitwise comparisons, you need to wrap those in (). This may seem abstract but will be important soon. Like really soon.
[51]:
a[(a>.3) & (a<.5)] = 9
a
[51]:
array([[0. , 9. , 0. , 0.51396335, 0. ],
[9. , 0. , 0. , 0. , 0. ],
[0. , 9. , 0. , 0. , 0.2838194 ],
[9. , 0. , 9. , 0. , 9. ],
[0. , 0. , 0. , 9. , 0. ]])
there are times when it’s useful to have a list of indices meeting some condition. `np.where <https://numpy.org/doc/stable/reference/generated/numpy.where.html>`__ will hook you up. (also check out `nonzero <https://numpy.org/doc/stable/reference/generated/numpy.nonzero.html>`__ and `argwhere <https://numpy.org/doc/stable/reference/generated/numpy.argwhere.html>`__ for some nuanced options)
[52]:
a = np.random.random((3,3))
a
[52]:
array([[0.0500235 , 0.226205 , 0.1891304 ],
[0.28087644, 0.39935058, 0.50445187],
[0.256149 , 0.93937672, 0.54376712]])
[53]:
idx = np.where(a<0.5)
idx
[53]:
(array([0, 0, 0, 1, 1, 2]), array([0, 1, 2, 0, 1, 0]))
[54]:
a
[54]:
array([[0.0500235 , 0.226205 , 0.1891304 ],
[0.28087644, 0.39935058, 0.50445187],
[0.256149 , 0.93937672, 0.54376712]])
[55]:
a[idx]
[55]:
array([0.0500235 , 0.226205 , 0.1891304 , 0.28087644, 0.39935058,
0.256149 ])
TEST YOUR SKILLS #1
Let’s calculate the amount of material lost from Mt. St. Helens in the 1980 eruption. We have the before and after elevation arrays in the data folder noted in the next cell. We will need to load them up.
The before and after files are the same dimensions, but they have some zeros around the edges indicating “nodata” values.
Check to see - are the zeros in the same place in both arrays? (
np.whereand friends can help with that).If there are no-data zeros in one array at a different location than the other array, what happens if you look at the difference?
assume each pixel is 25 x 25 feet and the elevation arrays are provided in meters to calculate a volumetric difference between before and after arrays.
[56]:
before_file = datapath / 'mt_st_helens_before.dat'
after_file = datapath / 'mt_st_helens_after.dat'
[ ]:
[ ]:
[ ]:
[ ]:
[ ]:
[ ]:
[ ]:
Views vs. Copies
Slice indexing returns a view That means if you change the slice, you change the original 🤔
[57]:
a
[57]:
array([[0.0500235 , 0.226205 , 0.1891304 ],
[0.28087644, 0.39935058, 0.50445187],
[0.256149 , 0.93937672, 0.54376712]])
[58]:
b = a[:2, :2]
b[1,1] = 10
[59]:
b
[59]:
array([[ 0.0500235 , 0.226205 ],
[ 0.28087644, 10. ]])
[60]:
a
[60]:
array([[ 0.0500235 , 0.226205 , 0.1891304 ],
[ 0.28087644, 10. , 0.50445187],
[ 0.256149 , 0.93937672, 0.54376712]])
how can this happen??? id() returns the memory location a value is stored in within the computer
first check out where a and b are located
[61]:
id(a), id(b)
[61]:
(139705117669776, 139705118019568)
ok, but what about the actual data?
[62]:
id(a[1,1]), id(b[1,1])
[62]:
(139705117679760, 139705117679760)
[63]:
id(a[1,0]), id(b[1,0])
[63]:
(139705117682800, 139705117682800)
Array and Boolean indexing returns a copy. Operations on the copy do not affect the original array.
[64]:
list(range(2))
[64]:
[0, 1]
[65]:
c = a[a>.4]
c
[65]:
array([10. , 0.50445187, 0.93937672, 0.54376712])
[66]:
c[1] = 20
c
[66]:
array([10. , 20. , 0.93937672, 0.54376712])
[67]:
a
[67]:
array([[ 0.0500235 , 0.226205 , 0.1891304 ],
[ 0.28087644, 10. , 0.50445187],
[ 0.256149 , 0.93937672, 0.54376712]])
again, we can look at these memory addresses to confirm what’s happening
[68]:
id(a), id(c)
[68]:
(139705117669776, 139705118019856)
[69]:
id(a[1]), id(c[1])
[69]:
(139705118023120, 139705117678608)
Reshaping and Stacking Arrays
Reshaping of arrays is easy to do with the np.reshape function. The function works by taking an array and desired shape, and then returning a new array with that shape. Note, however, that the requested shape must be consistent with the array that is passed in. The syntax is:
np.reshape(a, (newshape))
Arrays also have a reshape method, which means you can use the following form:
a.reshape( (newshape) )
Example follows.
[70]:
a = np.arange(9)
print('a: ', a)
b = np.reshape(a, (3,3))
print('b: ', b)
a: [0 1 2 3 4 5 6 7 8]
b: [[0 1 2]
[3 4 5]
[6 7 8]]
just to hammer home to view vs. copy behavior, look at a and b more closely
[71]:
a
[71]:
array([0, 1, 2, 3, 4, 5, 6, 7, 8])
[72]:
b.base
[72]:
array([0, 1, 2, 3, 4, 5, 6, 7, 8])
[73]:
b
[73]:
array([[0, 1, 2],
[3, 4, 5],
[6, 7, 8]])
[74]:
b[1,1] = 999
[75]:
a
[75]:
array([ 0, 1, 2, 3, 999, 5, 6, 7, 8])
[76]:
b
[76]:
array([[ 0, 1, 2],
[ 3, 999, 5],
[ 6, 7, 8]])
[77]:
id(a[1]), id(b[0,1]), id(b.base[1])
[77]:
(139705117678064, 139705117678064, 139705117678064)
hstack and vstack
hstack and vstack can be used to add columns to an array or rows to an array.
[78]:
#vstack example -- add a row to an array
a = np.zeros((3, 3), dtype=float)
print(a)
b = np.vstack((a, np.array([2, 2, 2])))
print(b)
print('The shape of b is ', b.shape)
[[0. 0. 0.]
[0. 0. 0.]
[0. 0. 0.]]
[[0. 0. 0.]
[0. 0. 0.]
[0. 0. 0.]
[2. 2. 2.]]
The shape of b is (4, 3)
Flattening arrays
oftentimes we need to flatten a 2D array to one dimension the ndarray.flat attribute provides a means of iterating over a numpy array in one-dimension
[79]:
[value for value in b.flat]
[79]:
[np.float64(0.0),
np.float64(0.0),
np.float64(0.0),
np.float64(0.0),
np.float64(0.0),
np.float64(0.0),
np.float64(0.0),
np.float64(0.0),
np.float64(0.0),
np.float64(2.0),
np.float64(2.0),
np.float64(2.0)]
if we need a 1D copy returned instead, we can use the ndarray.flatten method
[80]:
b.flatten()
[80]:
array([0., 0., 0., 0., 0., 0., 0., 0., 0., 2., 2., 2.])
.ravel() returns a view instead of a copy when possible
[81]:
c = b.ravel()
c[1] = 4
b
[81]:
array([[0., 4., 0.],
[0., 0., 0.],
[0., 0., 0.],
[2., 2., 2.]])
[82]:
c
[82]:
array([0., 4., 0., 0., 0., 0., 0., 0., 0., 2., 2., 2.])
TEST YOUR SKILLS #2
In an earlier exercise, you made x and y using the following lines of code. Now use vstack to add another row to y that has the cosine of x. Then plot them both on the same figure.
hint
plt.plot(x,y)makes plots of arrays x and y
[83]:
x = np.linspace(0, 2*np.pi)
y = np.sin(x)
[ ]:
[ ]:
[ ]:
[ ]:
[ ]:
[ ]:
Masking an Array
Masking is the process of performing array operations on a specific set of cells, called a mask. A mask is a logical array with the same shape as the array it is applied to. Here is an example. Also, note that np.where contains arguments that can accomplish a similar result.
[84]:
#create a 10 by 10 array
a = np.arange(100).reshape((10,10))
print('a:\n', a)
a:
[[ 0 1 2 3 4 5 6 7 8 9]
[10 11 12 13 14 15 16 17 18 19]
[20 21 22 23 24 25 26 27 28 29]
[30 31 32 33 34 35 36 37 38 39]
[40 41 42 43 44 45 46 47 48 49]
[50 51 52 53 54 55 56 57 58 59]
[60 61 62 63 64 65 66 67 68 69]
[70 71 72 73 74 75 76 77 78 79]
[80 81 82 83 84 85 86 87 88 89]
[90 91 92 93 94 95 96 97 98 99]]
[85]:
print('mask array for a == 1:\n', a[:, :] == 1)
mask array for a == 1:
[[False True False False False False False False False False]
[False False False False False False False False False False]
[False False False False False False False False False False]
[False False False False False False False False False False]
[False False False False False False False False False False]
[False False False False False False False False False False]
[False False False False False False False False False False]
[False False False False False False False False False False]
[False False False False False False False False False False]
[False False False False False False False False False False]]
[86]:
# We can create a mask array as follows
# enclosing the conditional statement in parentheses is added for clarity
mask = (a[:,:]>=75)
print(mask)
#Now we can use the mask to set values
a[mask] = 100
print(a)
[[False False False False False False False False False False]
[False False False False False False False False False False]
[False False False False False False False False False False]
[False False False False False False False False False False]
[False False False False False False False False False False]
[False False False False False False False False False False]
[False False False False False False False False False False]
[False False False False False True True True True True]
[ True True True True True True True True True True]
[ True True True True True True True True True True]]
[[ 0 1 2 3 4 5 6 7 8 9]
[ 10 11 12 13 14 15 16 17 18 19]
[ 20 21 22 23 24 25 26 27 28 29]
[ 30 31 32 33 34 35 36 37 38 39]
[ 40 41 42 43 44 45 46 47 48 49]
[ 50 51 52 53 54 55 56 57 58 59]
[ 60 61 62 63 64 65 66 67 68 69]
[ 70 71 72 73 74 100 100 100 100 100]
[100 100 100 100 100 100 100 100 100 100]
[100 100 100 100 100 100 100 100 100 100]]
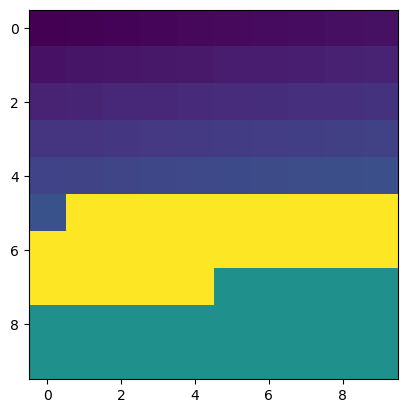
Multi-Conditional Masking
For more complicated masks, we can bring back the bitwise operators from above (&, |, and ^)
[87]:
b = a.copy()
[88]:
mask = (b[:,:]>50) & (b[:,:]<75)
print(b)
plt.imshow(mask)
[[ 0 1 2 3 4 5 6 7 8 9]
[ 10 11 12 13 14 15 16 17 18 19]
[ 20 21 22 23 24 25 26 27 28 29]
[ 30 31 32 33 34 35 36 37 38 39]
[ 40 41 42 43 44 45 46 47 48 49]
[ 50 51 52 53 54 55 56 57 58 59]
[ 60 61 62 63 64 65 66 67 68 69]
[ 70 71 72 73 74 100 100 100 100 100]
[100 100 100 100 100 100 100 100 100 100]
[100 100 100 100 100 100 100 100 100 100]]
[88]:
<matplotlib.image.AxesImage at 0x7f0f98b0a850>
[89]:
b[mask] = 200
print(b)
plt.imshow(b)
[[ 0 1 2 3 4 5 6 7 8 9]
[ 10 11 12 13 14 15 16 17 18 19]
[ 20 21 22 23 24 25 26 27 28 29]
[ 30 31 32 33 34 35 36 37 38 39]
[ 40 41 42 43 44 45 46 47 48 49]
[ 50 200 200 200 200 200 200 200 200 200]
[200 200 200 200 200 200 200 200 200 200]
[200 200 200 200 200 100 100 100 100 100]
[100 100 100 100 100 100 100 100 100 100]
[100 100 100 100 100 100 100 100 100 100]]
[89]:
<matplotlib.image.AxesImage at 0x7f0f98b53b10>
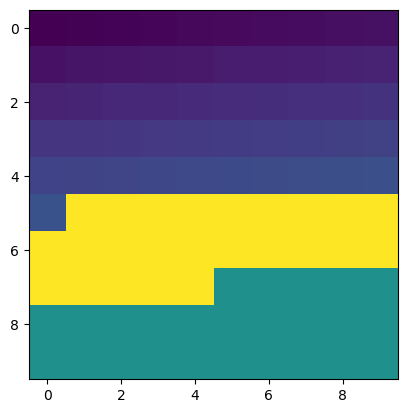
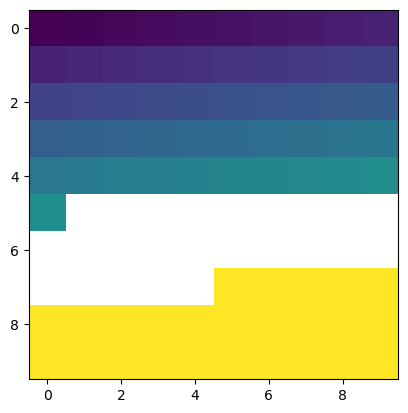
Masked arrays provide a convenient way to explicitly handle nan values in the same object
[90]:
b_masked = np.ma.masked_array(b, mask=mask)
plt.imshow(b_masked)
[90]:
<matplotlib.image.AxesImage at 0x7f0f98bdce10>
Record Arrays
Record arrays, also known as structured arrays, are a great way to store columns of data that have different types. They can be created by specifying a dtype that defines the columns. For example:
dtype=[('x', int), ('y', float), ('z', int)])
Now, let’s use this dtype to create an array with ones in it.
[91]:
dtype=[('x', int), ('y', float), ('z', int)]
a = np.ones( (10), dtype=dtype)
print(a)
[(1, 1., 1) (1, 1., 1) (1, 1., 1) (1, 1., 1) (1, 1., 1) (1, 1., 1)
(1, 1., 1) (1, 1., 1) (1, 1., 1) (1, 1., 1)]
[92]:
#we can access each column by using the column names
print(a['x'])
print(a['y'])
print(a['z'])
[1 1 1 1 1 1 1 1 1 1]
[1. 1. 1. 1. 1. 1. 1. 1. 1. 1.]
[1 1 1 1 1 1 1 1 1 1]
[93]:
#we can also change how we view the record array so that we can access columns more easily
a = a.view(np.recarray)
print(a.x)
print(a.y)
print(a.z)
[1 1 1 1 1 1 1 1 1 1]
[1. 1. 1. 1. 1. 1. 1. 1. 1. 1.]
[1 1 1 1 1 1 1 1 1 1]
[94]:
#to add a column, use vstack!
dt = [('name', 'S15')]
string_column = np.empty((10), dtype=dt).view(np.recarray)
string_column.name = 'text string'
#we can use a merge_arrays function to add a column
import numpy.lib.recfunctions as rfn
b = rfn.merge_arrays((a, string_column), flatten = True, usemask = False)
#we need to convert b to a recarray to access individual columns as before
b = b.view(np.recarray)
print('Now we have appended string_column to a: \n', b)
print('b is of shape: ', b.shape)
print(b.dtype.names)
Now we have appended string_column to a:
[(1, 1., 1, b'text string') (1, 1., 1, b'text string')
(1, 1., 1, b'text string') (1, 1., 1, b'text string')
(1, 1., 1, b'text string') (1, 1., 1, b'text string')
(1, 1., 1, b'text string') (1, 1., 1, b'text string')
(1, 1., 1, b'text string') (1, 1., 1, b'text string')]
b is of shape: (10,)
('x', 'y', 'z', 'name')
Testing your Skills
Become familiar with recarrays by creating one that has four columns and 100 rows. In the first column, put an integer that starts at 99 and decreases to 0. In the second column, put a text string that has ‘row n’, where n is the actual row value. In the third column put a random number, and in the fourth column, put your name.
[95]:
#do the exercise here
genfromtxt and Record Arrays
genfromtxt can automatically create a record array if the following arguments are provided (dtype=None, names=True). When these arguments are set this way, genfromtxt will automatically determine the type for each column and will use the first non-commented line of the data file as column labels.
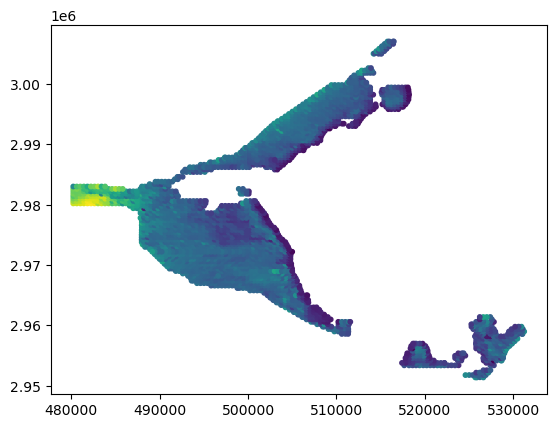
In the 03_numpy folder, there is a csv file called ahf.csv. This file contains airborne helicopter measurements of elevation taken at points in the everglades. This data was downloaded from: http://sofia.usgs.gov/exchange/desmond/desmondelev.html.
In the following cell, we use genfromtxt to load this csv file into a recarray. The beauty of this is that genfromtxt automatically determines the type of information in each columns and fills the array accordingly. When this is done correctly, we can access each column in the array using the column text identifier as follows.
[96]:
#specify the file name
fname = datapath / 'ahf.csv'
print('Data will be loaded from: ', fname)
#load the array
a = np.genfromtxt(fname, dtype=None, names=True, delimiter=',')
#print information about the array
print('dypte contains the column information: ', a.dtype)
print()
print('this is the array: ', a)
print()
print('this is just the column names: ', a.dtype.names)
print()
#now we can create scatter plot of the points very easily using the plt.scatter command
#the nice thing here is that we access the array columns directly using the column names
plt.scatter(a['X_UTM'], a['Y_UTM'], c=a['ELEV_M'], s=10)
Data will be loaded from: data/numpy/ahf.csv
dypte contains the column information: [('ID', '<i8'), ('X_UTM', '<f8'), ('Y_UTM', '<f8'), ('ELEV_M', '<f8'), ('QUAD_NAME', '<U15'), ('VEG_FS', '<U18'), ('SUR_METHOD', '<U3'), ('SUR_INFO', '<U20'), ('SUR_FILE', '<U12')]
this is the array: [( 1, 525705.77, 2951410.9 , 4.87, 'Belle Glade', 'Broadleaf Emergent', 'AHF', 'BE33A26506 20061004Y', 'BE061004.PUB')
( 2, 525875.53, 2951395.58, 4.39, 'Belle Glade', 'Shrub', 'AHF', 'BE33A26506 20061004Y', 'BE061004.PUB')
( 3, 526235.55, 2951429.23, 3.73, 'Belle Glade', 'Shrub', 'AHF', 'BE33A26506 20061004Y', 'BE061004.PUB')
...
(2863, 527017.04, 2961403.84, 4.85, 'Pahokee', 'Shrub', 'AHF', 'PA13L26906 20061012Y', 'PA061012.PUB')
(2864, 526621.4 , 2961398.48, 4.98, 'Pahokee', 'Shrub', 'AHF', 'PA13L26906 20061012Y', 'PA061012.PUB')
(2865, 526221.09, 2961407.38, 3.07, 'Pahokee', 'Knot Grass', 'AHF', 'PA13L26906 20061012Y', 'PA061012.PUB')]
this is just the column names: ('ID', 'X_UTM', 'Y_UTM', 'ELEV_M', 'QUAD_NAME', 'VEG_FS', 'SUR_METHOD', 'SUR_INFO', 'SUR_FILE')
[96]:
<matplotlib.collections.PathCollection at 0x7f0f98a1bb60>
Reading a Wrapped MODFLOW Array
It is unlikely that there will be time for this, but the following function is a quick hack that can be used to read a MODFLOW external array where the columns are wrapped. Note that you cannot use np.genfromtxt or np.loadtxt to do this if the columns are wrapped.
Keep this little function in your back pocket in case you need it one day. If you have time, read bottom.txt in the 04_numpy directory and plot it. This array has 142 rows and 113 columns.
[97]:
# This is a little goodie that you might need one day.
def readarray(fname, nrow, ncol):
f = open(fname, 'r')
arraylist = []
for line in f:
linelist = line.strip().split()
for v in linelist:
dtype = np.int
if '.' in v:
dtype = np.float
arraylist.append(dtype(v))
f.close()
return np.reshape(np.array(arraylist[:ncol*nrow]), (nrow, ncol))
[98]:
#read bottom.txt here
[ ]:
[ ]:
[99]:
# answer for earlier sk test
dt=[('col1', int), ('col2', 'S10'), ('col3', float), ('col4', 'S20')]
myrecarray = np.zeros((100), dtype=dt).view(np.recarray)
myrecarray.col1[:] = np.arange(99,-1, -1)
myrecarray.col2[:] = 'row '
myrecarray.col3[:] = np.random.random((100))
myrecarray.col4[:] = 'cdl'
print(myrecarray.dtype.names)
print(myrecarray)
('col1', 'col2', 'col3', 'col4')
[(99, b'row ', 0.90135304, b'cdl') (98, b'row ', 0.96405421, b'cdl')
(97, b'row ', 0.99774945, b'cdl') (96, b'row ', 0.91527025, b'cdl')
(95, b'row ', 0.37885869, b'cdl') (94, b'row ', 0.22703861, b'cdl')
(93, b'row ', 0.04027432, b'cdl') (92, b'row ', 0.6516079 , b'cdl')
(91, b'row ', 0.25802428, b'cdl') (90, b'row ', 0.06884277, b'cdl')
(89, b'row ', 0.0282429 , b'cdl') (88, b'row ', 0.12862866, b'cdl')
(87, b'row ', 0.25157918, b'cdl') (86, b'row ', 0.01341249, b'cdl')
(85, b'row ', 0.66671693, b'cdl') (84, b'row ', 0.21307207, b'cdl')
(83, b'row ', 0.11487151, b'cdl') (82, b'row ', 0.60044098, b'cdl')
(81, b'row ', 0.25482094, b'cdl') (80, b'row ', 0.2617049 , b'cdl')
(79, b'row ', 0.03247547, b'cdl') (78, b'row ', 0.83659146, b'cdl')
(77, b'row ', 0.27334002, b'cdl') (76, b'row ', 0.12284996, b'cdl')
(75, b'row ', 0.73064073, b'cdl') (74, b'row ', 0.13985146, b'cdl')
(73, b'row ', 0.7149793 , b'cdl') (72, b'row ', 0.6336356 , b'cdl')
(71, b'row ', 0.8728234 , b'cdl') (70, b'row ', 0.42475953, b'cdl')
(69, b'row ', 0.79974463, b'cdl') (68, b'row ', 0.63323331, b'cdl')
(67, b'row ', 0.04829164, b'cdl') (66, b'row ', 0.3184271 , b'cdl')
(65, b'row ', 0.61254626, b'cdl') (64, b'row ', 0.63568253, b'cdl')
(63, b'row ', 0.4019832 , b'cdl') (62, b'row ', 0.9372371 , b'cdl')
(61, b'row ', 0.1337389 , b'cdl') (60, b'row ', 0.06671253, b'cdl')
(59, b'row ', 0.90436017, b'cdl') (58, b'row ', 0.53295158, b'cdl')
(57, b'row ', 0.01004185, b'cdl') (56, b'row ', 0.88817216, b'cdl')
(55, b'row ', 0.21463129, b'cdl') (54, b'row ', 0.15790673, b'cdl')
(53, b'row ', 0.46973538, b'cdl') (52, b'row ', 0.22513857, b'cdl')
(51, b'row ', 0.90436148, b'cdl') (50, b'row ', 0.57748252, b'cdl')
(49, b'row ', 0.72427686, b'cdl') (48, b'row ', 0.90962589, b'cdl')
(47, b'row ', 0.34514263, b'cdl') (46, b'row ', 0.86043323, b'cdl')
(45, b'row ', 0.65849877, b'cdl') (44, b'row ', 0.95631403, b'cdl')
(43, b'row ', 0.56353047, b'cdl') (42, b'row ', 0.93007401, b'cdl')
(41, b'row ', 0.06154551, b'cdl') (40, b'row ', 0.56917493, b'cdl')
(39, b'row ', 0.17358241, b'cdl') (38, b'row ', 0.40892863, b'cdl')
(37, b'row ', 0.23319783, b'cdl') (36, b'row ', 0.18090675, b'cdl')
(35, b'row ', 0.96587788, b'cdl') (34, b'row ', 0.29180683, b'cdl')
(33, b'row ', 0.47007749, b'cdl') (32, b'row ', 0.96231664, b'cdl')
(31, b'row ', 0.90348158, b'cdl') (30, b'row ', 0.99037444, b'cdl')
(29, b'row ', 0.80692634, b'cdl') (28, b'row ', 0.63833601, b'cdl')
(27, b'row ', 0.79443216, b'cdl') (26, b'row ', 0.44397311, b'cdl')
(25, b'row ', 0.85100564, b'cdl') (24, b'row ', 0.34961097, b'cdl')
(23, b'row ', 0.61941866, b'cdl') (22, b'row ', 0.86452216, b'cdl')
(21, b'row ', 0.70634454, b'cdl') (20, b'row ', 0.94260614, b'cdl')
(19, b'row ', 0.66310714, b'cdl') (18, b'row ', 0.21677667, b'cdl')
(17, b'row ', 0.29911287, b'cdl') (16, b'row ', 0.27680841, b'cdl')
(15, b'row ', 0.31012865, b'cdl') (14, b'row ', 0.79119114, b'cdl')
(13, b'row ', 0.36311873, b'cdl') (12, b'row ', 0.13704459, b'cdl')
(11, b'row ', 0.88141057, b'cdl') (10, b'row ', 0.70589897, b'cdl')
( 9, b'row ', 0.35187447, b'cdl') ( 8, b'row ', 0.75703958, b'cdl')
( 7, b'row ', 0.54112861, b'cdl') ( 6, b'row ', 0.01123787, b'cdl')
( 5, b'row ', 0.13839357, b'cdl') ( 4, b'row ', 0.97606031, b'cdl')
( 3, b'row ', 0.97496608, b'cdl') ( 2, b'row ', 0.98378633, b'cdl')
( 1, b'row ', 0.66101328, b'cdl') ( 0, b'row ', 0.16298012, b'cdl')]
Flow around a cylinder (from Mark Bakker)
The radial and tangential components of the velocity vector \(\vec{v}=(v_r,v_\theta)\) for inviscid fluid flow around a cylinder are given by
\(\begin{split} v_r&=U(1-R^2/r^2)\cos(\theta) \qquad r\ge R \\ v_\theta&=-U(1+R^2/r^2)\sin(\theta) \qquad r\ge R \end{split}\)
and is zero otherwise. The \(x\) and \(y\) components of the velocity vector may be obtained from the radial and tangential components as
\(\begin{split} v_x&=v_r\cos(\theta) - v_\theta\sin(\theta) \\ v_y &= v_r\sin(\theta) + v_\theta\cos(\theta) \end{split}\)
Write a function that returns the \(x\) and \(y\) components of the velocity vector for fluid flow around a cylinder with \(R=1.5\) and \(U=2\).
Test your function by making sure that at \((x,y) = (2,3)\) the velocity vector is \((v_x,v_y)=(2.1331, -0.3195)\).
Compute the \(x\) and \(y\) components of the velocity vector on a grid of 50 by 50 points where
xvaries from -4 to +4, andyvaries from -3 to 3.Plot the
vxandvyarrays usingplt.imshow.Create a stream plot using the cool function
plt.streamplot, which takes four arguments:x,y,vx,vy.
1D Solute Transport
A simple 1D transport analytical solution (Zheng and Bennet page 174; originally from Ogata and Banks, 1961):
\(\frac{C}{C_0} = \frac{1}{2} \left [ erfc \left ( \frac{x - v t}{\sqrt{4Dt}} \right ) + exp \left ( \frac{xv}{D} \right ) erfc \left ( \frac{x + v t}{\sqrt{4Dt}} \right ) \right ]\)
Make a plot of solute concentration as a function of distance and also as a function of time for different values of velocity and dispersion coefficient.